I've been brushing up on my web development skills with the Web Development Bootcamp course through Udemy. The course involves downloading a lot of projects, bundled as zip files. Very quickly I tired of moving the zip file to my projects folder and then unzipping the file. It's only a couple of steps, but it becomes very repetitious and monotonous, an ideal task for automation.
The initial setup steps:
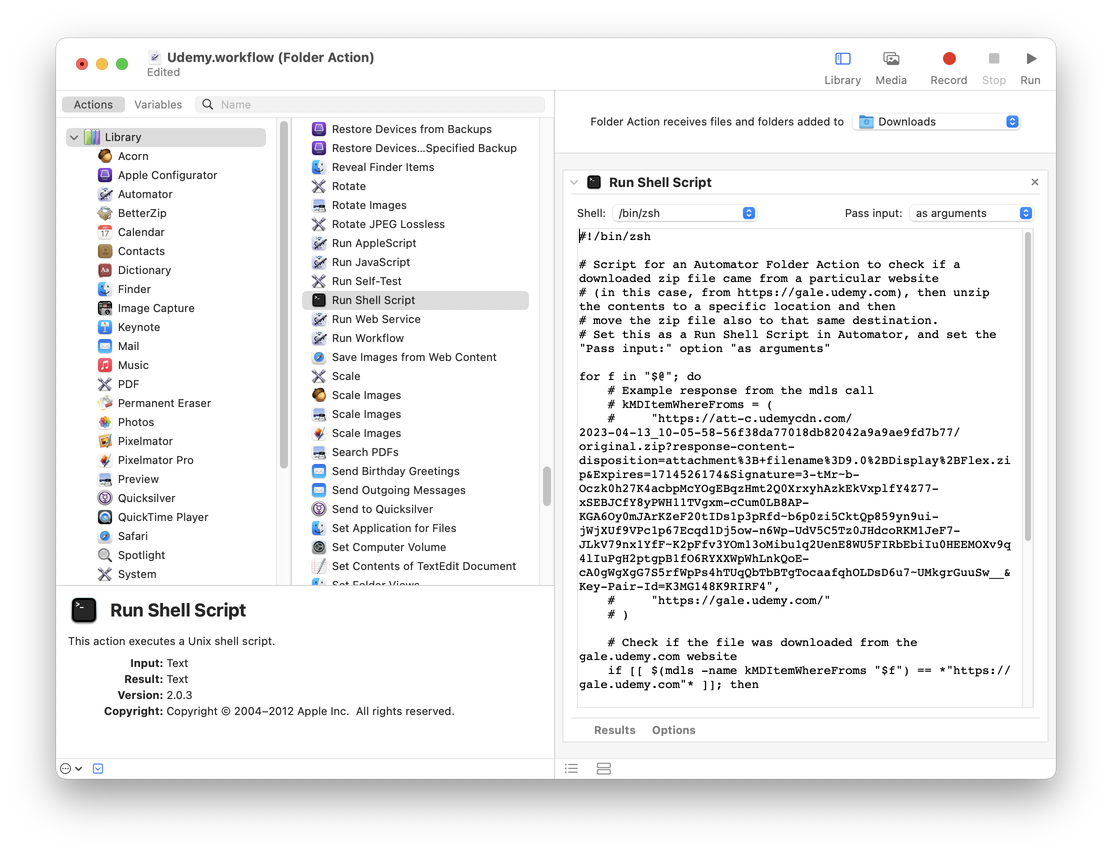
Open Automator (Applications > Automator.app)
Select: File > New > Folder Action
Change the Folder Actions receives files and folders added to folder to Downloads
Add a Run Shell Script action
Change Pass input: from to stdin to as arguments
Write the shell script
The shell script:
Note: This script makes use of the zsh shell, but bash also seems to work, as well. This script was tested on macOS Ventura 13.6.6, but it should hopefully work on an array of other versions (older and newer) of macOS.
The Folder Action passes the downloaded file as an argument (and not via stdin, otherwise this script won't work), and then the script iterates over the supplied argument(s) $@.
If you open up the Get Info panel on a file, the More Info: section may contain information detailing where a file originated. To check where a file a file might have been downloaded from, the mdls command is used to check for the file's metadata attributes and the kMDItemWhereFroms option returns an array of possible values. One example of inspecting one of these zip files:
The script just takes the output from the mdls call as a string and then checks if the gale.udemy.com URL is found, which indicates that the file originated from the Udemy website. All other files will be ignored.
The final steps involve unzipping the file into the destination folder and finally moving the original zip file (optional, but good as a cleanup process).
Challenges
This script is fairly short, but it required a number of iterations to get everything to work properly. I started by writing a shell script and running it against a downloaded file, but it doesn't work exactly the same as when it is treated as a script within Automator.
The first challenge was to figure out how to extract the Where From data via a script. Fortunately, mdls solved the initial problem. I initially thought I would have to parse out the data which returns as a CFArray object, but is is just a string in this context. One thing which didn't work initially was when I was creating the comparison string, I simply used "https://gale.udemy.com". This didn't work because the asterisks are required on both sides to act as wild cards. The fix is to compare against *"https://gale.udemy.com"* .
When I initialized the destination directory variable dst_dir, I initially surrounded the path ("~/Sites/the-complete-web-development-bootcamp/") with quotes as a safety measure in case there were ever spaces. However this caused a different issue in properly resolving the path, so I was getting No such file or directory errors when trying to work with that directory. After some research I discovered that using quotes caused the path with the ~ to not resolve properly.
In my initial script, I first moved the zip file to the destination directory, then changed to that new directory, and finally would unzip it. This worked properly when I ran the script directly, but when it was run within Automator, nothing seemed to work. Trying to debug such issues can be perplexing so I ended up running the unzip command and then piped any errors to a text file (e.g. unzip TheFile.zip &> errors.txt). After doing this, I was able to get a useful error:
unzip: cannot find or open /Users/chad/Downloads/TheFile.zip, /Users/chad/Downloads/TheFile.zip.zip or /Users/chad/Downloads/TheFile.zip.ZIP.
When I was running the shell script directly from the Downloads folder, I would make a call like this: ./udemy.sh TheFile.zip . In this example, the name of the file being passed in as an argument would be just TheFile.zip, but when it is passed in through the Folder Action, it is the entire file path, which tripped up my initial approach.
My workaround for this issue was to just unzip the archive from the Downloads folder, but set the -d flag and use the dst_dir as the destination path. Once that is completed, I then moved the zip file to the destination folder.
Bonus Challenge
Another thing I tried, which was eventually abandoned, was to create a name for an enclosing folder where to unzip the contents of the archive. The enclosing folder would share the same name as the zip file, so I needed a way to take the file name and just strip off the file extension. This introduced me to some more UNIX commands, basename and its associated dirname. After doing more research, I tried two methods to isolate just the name of the file. One method worked for me, while the other did not.
# Get the file's name without the file suffix
filename="$f"
enclosing_folder=$(basename $filename) # This didn't work for me
enclosing_folder="${filename%.*}" # This does work to get just the file name
Conclusion
For what I had originally expected would be a somewhat simple task of automation to relieve a minor burden, resulted in becoming an interesting and frustrating experience as I fought against the nit-picky syntax of shell scripting and trying to integrate it with a Folder Action. The end result is a minimal amount of code, but not before going through several rounds of experimentation to carve the code down to its functional essence.
Setting uniform rounded corners on a view in Swift is a relatively trivial task by setting the cornerRadius property on the view's layer. But what if not all of the corners need to be rounded? Or different radii are needed for each corner? This post goes over several different methods to approach these issues in Swift and SwiftUI.
Swift Examples
Example 1
This first example shows how to set the top two corners of the image to have a corner radius of 16 by setting the layer's maskedCorners property.
This next example makes use of a a UIBezierPath and a masking layer to round off the two corners on the right. It's not as straightforward as the previous example, but its approach will prove useful for the next example.
This is the most complex example, but the most flexible. As demonstrated in Example 2, a UIBezierPath and CAShapeLayer are used to create a mask to create an image with custom rounded corners. Whereas Example 2 used a rounded rectangle to predefine the shape of the path, this example creates its own shape using a combination of lines and arcs, which results in a rectangular-like shape with different sized rounded top corners. This example can be extended with a variety of shapes, such as a star.
let imageHeight = stockImageView.bounds.height
let imageWidth = stockImageView.bounds.width
let topLeftRadius = imageHeight / 2.0
let topRightRadius = 16.0
let customBezierMask = UIBezierPath()
// Starting point
customBezierMask.move(to: CGPoint(x: topLeftRadius, y: 0.0))
// Top line
customBezierMask.addLine(to: CGPoint(x: imageWidth-topRightRadius, y: 0.0))
// Top right corner with a radius of 16.0
customBezierMask.addArc(withCenter: CGPoint(x: imageWidth-topRightRadius, y: topRightRadius), radius: topRightRadius, startAngle: 3 * .pi/2, endAngle: 0, clockwise: true)
// Right line
customBezierMask.addLine(to: CGPoint(x: imageWidth, y: imageHeight))
// Bottom line
customBezierMask.addLine(to: CGPoint(x: 0.0, y: imageHeight))
// Left line
customBezierMask.addLine(to: CGPoint(x: 0.0, y: imageHeight - topLeftRadius))
// Top left corner with a radius that is half the height of the image
customBezierMask.addArc(withCenter: CGPoint(x: topLeftRadius, y: imageHeight - topLeftRadius), radius: topLeftRadius, startAngle: .pi, endAngle: 3 * .pi/2, clockwise: true)
let maskLayer = CAShapeLayer()
maskLayer.path = customBezierMask.cgPath
stockImageView.layer.mask = maskLayer
SwiftUI Examples
Example 1
This first SwiftUI example is modeled after Example 3 with the different rounded corners. Some of the principles are similar by using a custom Path, but there are also notable differences in the implementations between Swift and SwiftUI.
Instead of applying a UIBezierPath to a CAShapeLayer, a struct which adheres to the Shape protocol is used, and the Path is defined inside the struct.
UIBezierPath uses the addArc() method to define how to draw the rounded corners, Path uses the slightly different method addRelativeArc(), which seems a little more straightforward (and it can accept Angle values which can be defined using either degrees or radians).
In SwiftUI, Image calls clipShape() on a Shape struct. There is also a mask() method which can be used in some cases, but clipShape() is better for this example. The previous Swift example applies a mask layer.
Example 2
An even easier approach for this particular technique with different rounded corners is to use the .clipShape() method with a .rect that has custom radii via the RectangleCornerRadii struct. This is a far simpler method to produce the same results.
Using a custom path can be useful for creating unique shapes (such as a star), but for this demonstration which focused on providing rounded corners to an image, there are alternate solutions which don't require nearly as much code. In particular, this final SwiftUI example leverages the power of new functionality provided in this newer UI framework.
Integrated AppleScript with a Mac application, which resulted in me rebooting the Permanent Eraser 3 project once again, except this time with older machines and tech in mind.
The last few months of 2023 were spent writing a short story and starting the third draft of my novel, but once I wrapped that up, I began my work on my first Playdate game in earnest. The 1-bit dither plug-in is handy for some of the art. I also got the book Pixels Forever which has some interesting insights on pixel art. For a number of solo game devs, they tend to have their strengths and weaknesses — I'm strong with programming experience, but far weaker when it comes to art. Last year I declared 2023 to be the year of the Playdate, and while I started a number of projects to work towards my first Playdate game, it won't be until at least this year before something tangible will be available. Even for a relatively small game, there are many, many details to tackle to craft a decent game. The effort I've seen other game devs put into their own Playdate games has been astounding.
Continuing with AGS Mac ports for older and newer games.
Perhaps get back to working on Permanent Eraser 3 if the interest strikes me. So much of my time and energy for the past few years have been focusing on game-related projects, and Permanent Eraser is one of my oldest Mac projects which is still around. There are still a lot of great ideas I'd like to implement for this application which never made it into version 2.
I have a couple of other programming posts in mind, and hopefully I will put together the energy to write them. But if I don't manage that, here's the source code for these little projects:
Continuing my research and implementation of dithering techniques, I have turned my attention to 1-bit ordered dithering methods, useful for creating graphics for the Playdate, a quirky, monochrome, handheld console (with a crank).
There are many dithering techniques available, but they are divided into two principle sections: ordered and error diffusion. This article will focus on the former.
While error diffusion methods (especially the Floyd-Steinberg algorithm) are popular ways to create dithering effects, ordered dithering has the advantage for speed and also provides for a distinctive appearance, such as the gradient sky in the EGA version of Secret of Monkey Island.
In certain cases, ordered dithering is necessary for its speed or to be applied as a renderer, such as in The Return of the Obra Dinn.
This post will cover two programs which built up to creating a plug-in for Acorn to generate 1-bit images using an ordered dither algorithm.
Ordered Dithering Matrices - ordered_dithering.c
To implement ordered dithering, a matrix pattern is generated and is used as a tiled mask over the original image. The matrix can be a variety of sizes, such as 2x2 or 16x16. All of the examples I've seen have identical dimensions, so a 2x3 matrix is not used. The values assigned in the matrix are used to calculate the threshold value, whether a pixel should be set to white or black.
Matrix patterns
There does not seem to be one established way of how the matrix is populated. Even for a simple 2x2 matrix, I've noticed numerous examples in how the layout pattern is established, such as:
vs
vs
I tested these different patterns on the same image, and it didn't appear that there was any noticeable difference in the generated 1-bit image.
The algorithm in ordered_dithering.c populates a matrix with the order, but it does not necessarily determine the value of the threshold. The pixel color value generally has a range from 0.0 to 1.0 or from 0 to 255, and this determines how the threshold value is compared. This is dependent on the system and the programmer on how they want to calculate and compare the values. When one retrieves the color component from a pixel using Objective-C, each color component (red, green, blue) has a float value from 0.0 - 1.0, but this could be easily adjusted to be between 0 - 255 by multiplying the component value by the integer 255.
If one wants to compare integer values, then a possible 2x2 matrix could be:
This comes out very close to the pattern, once these values are divided by 255, which would be the appropriate 2x2 matrix when comparing values between 0.0 - 1.0.
However, the values do not necessarily need to be evenly spaced. One could set custom threshold values to populate the matrix which will adjust the calculated value of each pixel. This might be necessary if evenly spaced values do not produce the desired dithered effect. Such an example with a 2x2 matrix might be:
The values are not evenly spaced as in the prior example, but it might prove necessary if the contrast of an image is too light or dark, so an adjusted set of matrix values is needed.
This small program will generate an ordered matrix, and some of these matrices are used in the following program ordered_dither.m. The original code, by Stephen Hawley, originates from the book Graphics Gems and has been updated for a more modern version of C.
While this program generates a suitable ordered matrix, other examples and patterns are available, such as a 3x3 matrix or a magic square where each row and column adds up to the same value.
The Algorithm - ordered_dither.m
ordered_dither.m is a small Objective-C program which is the basis for the dithering algorithm used in the plug-in discussed in the next section. A number of the example matrices displayed in this program come from the ordered_dithering.c program, the Dither: Ordered and Floyd-Steinberg, Monochrome & Colored web page, and several text books listed in the References section.
This program iterates over each pixel of the given image, converts the color to a grayscale version, and then compares the pixel value to the matrix. When a larger matrix is used, there is more variability to the ordered pattern, which reduces the noticeable tiling effect. The 16x16 matrix seems optimal, especially since it contains 256 values, which lines up with the 0 - 255 range that most color components encompass.
OneBitOrderedDither - Acorn Plug-in
All of the research and experiments were built up to create another plug-in for Acorn (the first plug-in being AGIfier, which created low resolution images with an EGA color palette). This new plug-in, OneBitOrderedDither, generates a black and white image using a 16x16 ordered dither matrix. Much of the logic for this plug-in is based from the ordered_dither.m program.
I first built AGIfier several years ago using Xcode 11.3.1 and macOS 10.14. I started creating OneBitOrderedDither using Xcode 14.2 on macOS 13.5.2, but I noticed an issue when I created a new Bundle — the new project was missing the Info.plist file. I went back to my older machine and started up the new project under Xcode 11.3.1, which generated the expected Info.plist, then brought the project over to my newer computer.
Once I was finished coding the plug-in, I moved the bundle over to the ~/Library/Application Support/Acorn/Plug-Ins folder, but the plug-in was not displaying in Acorn's menus. I checked the Console log and came across some hints that the bundle was not building with an appropriate Apple Silicon architecture, in addition to an Intel version. I had to check the project settings and ensured that it was not supposed to build for only the active architecture (ONLY_ACTIVE_ARCH = NO;), and this seemed to resolve the problem.
If your browser did not unzip the file, double-click on the file OneBitOrderedDither.acplugin.zip so only OneBitOrderedDither.acplugin remains.
Copy the file OneBitOrderedDither.acplugin into the folder ~/Library/Application Support/Acorn/Plug-Ins
To Build and Install:
If you prefer to build from the source code and install the plug-in, follow these steps:
Get the source code by going to the
GitHub project, or pull down the code using the command:
git clone https://github.com/edenwaith/OneBitOrderedDither.git
Build the project
Find the plug-in: Product > Show Build Folder in Finder and then dig into the folders to find the file OneBitOrderedDither.acplugin
Copy the file OneBitOrderedDither.acplugin into the folder ~/Library/Application Support/Acorn/Plug-Ins
To run:
Open a file in Acorn
Select the menu Filter > Color Adjustment > 1-Bit Ordered Dither
My staple breakfast. The apples provide a nice texture and sweetness so no extra sugar is necessary.
Ingredients
⅔ cup + 1 ounce of water
¼ cup of Bob's Red Mill quick cooking steel-cut oats
1 dash of sea salt
1 dash of ground cloves
1 dash of ground nutmeg
2 dashes of ground cinnamon
⅓ cut Honeycrisp apple
Directions
Boil ⅔ cup of water in a small sauce pan. Add a dash of sea salt.
While the water is heating, prepare the oats. Pour ⅛ cup of steel-cut oats into a ¼ measuring cup. Put a dash of ground cloves and nutmeg on the oats. Shake the cup to even the oats.
Pour another 1/8 cup of oats into the cup. Then add a dash of ground cinnamon. Shake the cup to even the oats.
Once the water is boiling, pour the oats into the saucepan. Stir, then cover with a lid.
Lower the heat to low so the oats simmer.
While the oats are cooking, dice 1/3 of a medium-sized Honeycrisp apple.
Stir the oats occasionally. The oatmeal is done cooking when small bubbles start appearing, after ~10-15 minutes.
Pour the oatmeal into a bowl.
Add the sliced apples on the oatmeal.
Add a dash of cinnamon to the apples.
Drizzle 1 ounce of water onto the oatmeal and apples, then stir together.
I've baked dozens of types of breads, and this one still remains my favorite. Even before you bake the bread, it will make your kitchen smell amazing. Share and enjoy.
Ingredients
1 tablespoon dry yeast
2 cups warm water (110-115°F / 45°C)
2 tablespoons sugar
¼ cup olive oil (50g)
1 tablespoon sea salt
½ tablespoon dried basil
½ tablespoon dried oregano
½ tablespoon dried thyme
½ tablespoon dried rosemary
1 teaspoon garlic powder
1 teaspoon onion powder
½ cup Italian cheese
5-6 cups King Arthur bread flour (750g)
Directions
Mix yeast, warm water and sugar together in a large bowl.
Set aside for five minutes, or until the mixture becomes foamy.
Stir in olive oil, salt, herbs, garlic powder, onion powder, cheese and 3 cups flour into the yeast mixture. (Note: if you are using fresh herbs, instead of dried ones, double the amount from ½ to 1 tablespoon.)
Gradually mix in the next 2-3 cups of flour. Dough will be stiff. If the dough is still wet and sticky, gradually add one tablespoon of flour to the mixture.
Knead for 5 to 10 minutes, or until it is smooth and elastic.
Place in an oiled bowl, turning to cover the sides with oil.
Cover with a damp linen towel or greased plastic wrap.
Let the dough rise for 1 hour or until dough has doubled.
Punch down to release all the air.
Shape into two loaves. I like to roll the dough out into a 12" x 6" rectangle and then roll them up to form the loaves.
Place loaves on a pizza stone with parchment paper, a greased cookie sheet with cornmeal, a baguette pan, or into two 9x5 inch, greased pans.
Allow to rise for ½ hour again, until doubled in a warm place.
Score the loaves with a sharp knife or lame.
Spray the oven and the loaves with water if you want a little crispier crust.
Bake at 375°F (190°C) for 35 minutes.
Remove loaves from the oven and let them cool on wire racks for at least 15 minutes (ideally an hour) before slicing.
For the past several years I have been slowly undertaking the monolithic task of rewriting Permanent Eraser. However, such an endeavor has become quite the Sisyphean task as my efforts have come in random spurts between my various other projects. As an interim option, I looked at adding a new feature to the existing app, such as including AppleScript support (something I've been wanting to include for many, many years).
AppleScript Scriptable Resources
Here's a variety of links I went through on how to make a Mac app scriptable. The first three are the ones which I found the most useful and cut through a lot of the confusion of how to get things set up.
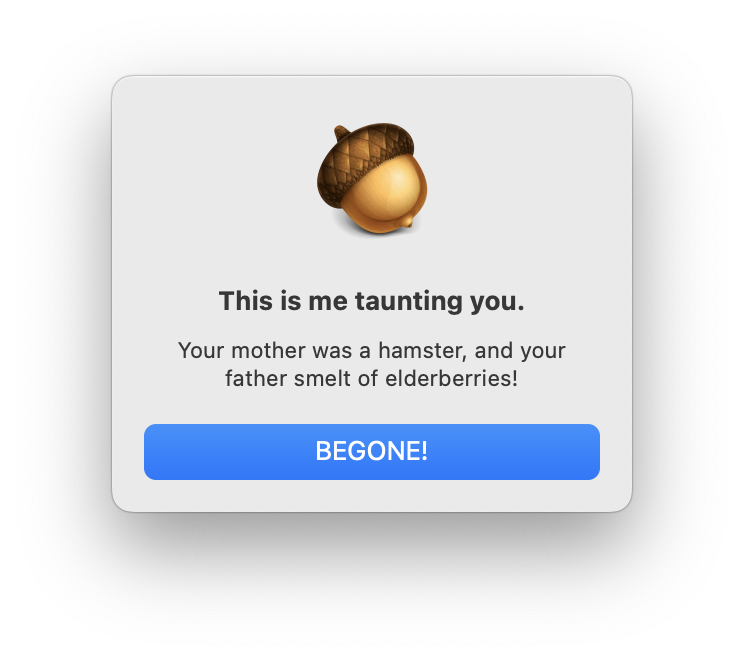
When I was doing research about scripting Mac apps, I took a look at other older programs and their AppleScript dictionaries. One of the examples I came across was the stalwart image editor Acorn which has an amusing taunt command, which results in this fun little dialog to appear:
Here's the AppleScript:
tell application "Acorn"
taunt
end tell
Permanent Eraser and AppleScript
After some initial experimentation, I was able to finally get AppleScript to communicate with Permanent Eraser. That's the good news, a basic proof of concept showed that it can work. The bad news is that much like when I tried to implement NSServices in Permanent Eraser the poor design choices made back in 2004 prevent it from working well. To get either NSServices or AppleScript to work with Permanent Eraser will require rearchitecting the app, but doing so will move it much closer to what I've hoped to fulfill with Permanent Eraser. While making Permanent Eraser 2 scriptable is not feasible at the moment, it has been quite an interesting and rewarding trip down another rabbit hole.
Over the past several years, I have been an ardent collector of boxed copies of Sierra computer games, particularly those from the Quest for Glory series. In the past year I finally managed to add an elusive gem to my QFG collection: クエスト フォー グローリィ, the Japanese version of Quest for Glory I (EGA).
I now have a physical copy, but the disks are 5.25" and are intended for a PC-98 computer. Even if this was intended for a standard IBM clone, I would not have a way to read the disks. I think the last time I used a computer with 5.25" drives was back in the late 90s, and even then, those were older computers running Windows 3.1. Fortunately, the internet is obliging in providing alternative methods in preserving old software, even if the original medium has become antiquated. The next trick was to figure out how to play this game on (slightly) more modern computers.
Emulating a PC-98 Computer
While I had not seen anyone play this version of Quest for Glory before, I had seen people stream the Japanese version of Police Quest II, so this indicated that it was possible to play PC-98 games on modern hardware, but this was an entirely new realm for me. My initial research pulled up a couple of articles and blog posts.
On my MacBook Pro, I first tried setting up np2sdl2 (version 0.86), one of the Neko Project II emulators, but it kept crashing when I launched it. I was a little too hopeful that things would "just work". I then started looking at the included file はじめにお読みください.txt, which is in Japanese, so it was difficult for me to parse out the instructions, but a couple of words were in English, such as BIOS.ROM, FONT.ROM, and https://www.libsdl.org/download-2.0.php. Going to the SDL link briefly showed a message that the webpage had been moved to GitHub, which at the time of this writing redirects to https://github.com/libsdl-org/SDL/releases/tag/release-2.26.2. This was one initial clue to why the app was crashing. I inspected the crash log, and it indicated that I needed to install the SDL2 library first. I then downloaded SDL2-2.26.2.dmg and installed those libraries. Now np2sdl2 no longer crashed. It started up, made a beep, checked its RAM...then showed a blank screen. I then placed the BIOS.ROM and FONT.ROM files in the same folder as the np2sdl2.app, but starting the app still resulted in a black screen. Any details to configure and troubleshoot are sparse, especially for the Mac version, which doesn't seem to be very well supported, but this is marginally better than Neko Project 21/W which doesn't even have a Mac version.
If I launch np2sdl2 from the command line (np2sdl2.app/Contents/MacOS/np2sdl2), it prints out twice "Device not found", but it does get to an actual screen, first asking how many devices, and a menu along the bottom. After setting the HDD to point to the disk image of the game, Quest for Glory I finally booted in Neko Project II.
After struggling with trying to get np2sdls2 to work, I tried another approach. The most straightforward solution I found was an old PowerPC application called "NP2 Carbon", even though the About Screen says "Neko Project II ver. 0.81a (Carbon)".
I tried this Carbon-based application on my PowerBook G4, and it was more promising than my first experiments with np2sdl2. Once I added FONT.ROM and BIOS.ROM into the same folder as the NP2 Carbon app, it booted up. This program uses a proper Mac menu bar, not some weird Windows 9X-looking interface inside of the window like np2sdl2 does. The audio was somewhat tinny on my PowerBook G4 (more on this in the Sounds section), but serviceable. The sound was somewhat off-putting, and I wasn't sure if I wanted to play through the entire game on the old Mac, but it's a nice option that PC-98 games can still be played on older Macs.
One shortcoming I noticed with both of these Neko Project II emulators is that neither one could go into Full Screen mode. On the PowerBook, the default window size wasn't too bad (since the screen resolution of the 2003 PowerBook was still years away from what Retina displays would provide), but the windowed screen on a MacBook Pro was not very enjoyable to squint at.
Another option I came across was to use DOSBox-X (not to be confused with the regular version of DOSBox), which does have PC-98 emulation. However, I encountered some snags here, as well, as the application could not find the dosbox.conf file. Unlike DOSBox, which has a preferences file in the standard ~/Library/Preferences folder on a Mac, DOSBox-X doesn't seem to have a corresponding preferences file. After reading up about this issue, it looks like the dosbox.conf file is instead saved in the home folder (not where it should be). A blank file was created, but that didn't help. I ended up copying over my "DOSBox 0.74 Preferences" file to dosbox.conf to my home folder. Perhaps copying the file https://github.com/joncampbell123/dosbox-x/blob/master/dosbox-x.reference.conf might be another option.
I then opened up the dosbox.conf file and changed the machine option to pc98. Restarting DOSBox-X then started up the PC-98 emulation. I then used the IMGMOUNT command to the mount the hard drive image (hdi) of QFG1.
IMGMOUNT C /Applications/DOSBox/dosbox/SIERRA/QGANTH/QG1J/QFG.hdi
c:
cd SIERRA
GLORY1.BAT
Note: To change to the new C: drive, since DOSBox-X is using a PC-98 style keyboard (I assume), not all of the keys are in the same place as on a US keyboard. The colon is the ' (apostrophe) key on my keyboard. This took a bunch of experimentation until I found the proper key. I address in the Issues section how I fixed a couple of keyboard issues, including when the CTRL key was not working for me.
Once I was able to switch over to the new mounted drive, I could see the standard game files. I started up the game and away I went.
It's been interesting trying to interact with this version since it is in Japanese (which I have pretty much no knowledge of). But using Google Translate, I was able to figure out a couple of commands in the game by phonetically typing in the words. Example phrases I figured out: look, run, sneak, rap door, climb, yes, hello, bye.
I get the sense that for non-English speakers, this was probably a similar experience by trying to learn English and when typing in commands, attempting to figure out the correct thing to type. (Consider that the Police Quest 1 phrase "administer field sobriety test" is challenging even for a native English speaker!) Fortunately, it is possible to switch the language input, or show a combination of both English and Japanese (CTRL+L).
What's New
I've lost count of how many times I've played this game since 1989, so it is always interesting to find something new or different. Besides the obvious language differences, I did encounter a couple of other things I hadn't discovered before.
If your climbing skill is not very high, you can fall off the castle walls. Do this enough times, and you can fall to your eventual death.
You can sell the Healer's ring at the Thieves' Guild for 35 silvers (which is not a good deal, the Healer gives you a lot more for returning it).
The Thieves' Guild password in this version is "Blowfish", which I don't ever recall being one of the possible passwords in the PC version of the game.
You can try to attack the fairies (but they will taunt you and then retaliate).
Screenshots
There are a handful of cases where the text and graphics were updated for the Japanese market, primarily the signs in town. Changing the language settings back to English will switch the signs back to English.
As a side note, it was interesting to see that full screenshots taken using DOSBox-X on my 2021 MacBook Pro rendered at a large 3024x1964 pixels, whereas screenshots in standard DOSBox will return the native resolution of the game (generally 320x200 for Sierra games of the late 80s). Since I took a good number of screenshots for this post, I needed some ways to batch resize and shrink down the image sizes. Many of these screenshots were between 1 to 2 MB in size, which adds up quickly when displaying ~40 screenshots on a single webpage. Loading 50+ MB for a single blog post is superfluous, especially if one is trying to load over a cellular connection, where bandwidth is still valuable, especially in areas of poor or slow connections.
I started off by installing the command line utility pngcrush via Homebrew with the command: brew install pngcrush, then ran it against a test screenshot to see what type of gains could be made.
% pngcrush test.png test-crushed.png
Recompressing IDAT chunks in test.png to test-crushed.png
Total length of data found in critical chunks = 1894274
Best pngcrush method = 6 (ws 15 fm 6 zl 9 zs 0) = 853831
CPU time decode 0.321226, encode 4.332043, other 0.009336, total 4.663681 sec
% ls -la test*png
-rw-r--r-- 1 chada staff 857474 Apr 30 21:18 test-crushed.png
-rw-r--r--@ 1 chada staff 1898113 Feb 2 18:54 test.png
That managed to reduce the original 1.9MB file down to more than half at 857KB. A great start, but there's plenty of room for improvement. Many of the screenshots I took on my PowerBook were under 100KB, so I wanted to get the reduced screenshots closer to that size. I then used sips (scriptable image processing system) to resize the image closer to the original game resolution. Even though the EGA version of QFG1 had a width of 320 pixels, I went for 640, which works out well for these types of posts.
That shrunk the 1.9MB file down to 388KB. Making progress. Let's compress the new image with pngcrush.
% pngcrush test-resized.png test-resized-crushed.png
Recompressing IDAT chunks in test-resized.png to test-resized-crushed.png
Total length of data found in critical chunks = 383535
Best pngcrush method = 7 (ws 15 fm 0 zl 9 zs 0) = 280199
CPU time decode 0.038348, encode 0.200314, other 0.002597, total 0.241483 sec
% ls -la test*.png
-rw-r--r-- 1 chada staff 857474 Apr 30 21:18 test-crushed.png
-rw-r--r-- 1 chada staff 284051 May 3 20:55 test-resized-crushed.png
-rw-r--r-- 1 chada staff 387543 May 3 20:54 test-resized.png
-rw-r--r--@ 1 chada staff 1898113 Feb 2 18:54 test.png
After resizing and then using pngcrush, I managed to reduce the 1.9MB image down to 284KB. A good improvement, but this could be even better. Weniger, aber besser. What if we try saving to another image format?
I resized and changed the image type to a JPEG (with 80% quality), which reduced the image down to 147KB, whereas the PNG version was nearly twice the size. Considering that there is no need for transparency in these screenshots, JPEG will work well, especially with the smaller file sizes. That was a reduction of down to 8% of the original file size! Not bad, at all.
Since I had an entire folder full of the original screenshots, I was able to resize all of the images and save them out to a new folder named "resized" with a single command:
For the most part, this game plays similar to the DOS version. The music does sound a little different, though, perhaps due to differences in the hardware I was using, in addition to how the PC-98 computer is emulated. This is my first exposure with a PC-98 game, so I'm not familiar if this is a standard variant between computer types or just how the emulators function.
However, there is a noticeable difference in the PC-98 version versus the traditional PC version. To give an example of how the game sounds, I made a recording of several scenes including Erana's Peace, the fight with the ogre, and the Kobold cave. Listen to hear the subtle differences in the Japanese version.
Trying to get a proper audio recording was an interesting process in itself, which resulted in using Snapz Pro X 2 on my PowerBook G4, instead of trying to jump through numerous hoops to get things to record well on a newer Mac. I briefly detailed some of the steps I took to make the recording in an older post about using the PowerBook.
When I got the game running on a PowerBook G4 under NP2 Carbon, the audio sounded pretty tinny, but that was likely due to the less-than-stellar speakers of a 20 year old laptop. Once I used headphones or external speakers, the PowerBook version sounded closer to the DOSBox-X version on my MacBook Pro. Considering that this sounded a lot better with dedicated speakers, perhaps I should have played from the PowerBook, but this did prove to be an interesting experiment to learn how to play a PC-98 game on various eras of hardware and software.
Issues
This version of QFG1 is missing some of the keyboard shortcuts that the English version uses, such as CTRL+A for "Ask about", but perhaps the concept to ask a question has different connotations in Japanese that wouldn't make sense for the dedicated shortcut. I was only able to figure out a handful of commands before learning that I could switch the game over to English (Sierra menu > Language, or CTRL+L). However, several shortcuts did remain, such as bringing up the stats or telling the time of day.
Unfortunately, the CTRL key was not registering under DOSBox-X 0.83.9. It worked fine in the NP2 Carbon emulator, so I initially assumed I needed to configure DOSBox-X in a different manner, perhaps to use a different keyboard layout. So I updated keyboardlayout in the dosbox.conf file to us. One can also set: pc-98 force ibm keyboard layout = true or the keyboard controller type to at. This also helped with typing from the command line, since the : was not the same key (use the ' key for that on a US layout).
Altering the configuration helped, but it still did not resolve the issue where CTRL was not recognized in Quest for Glory 1. After more research, I came across a bug report in DOSBox-X where the CTRL button not working (PC98mode). This sounded like the same issue I was having, and by upgrading to a newer version of DOSBox-X (version 2022.16.26, which is also Apple Silicon native. I don't believe the official DOSBox project has been updated to run on Apple Silicon processors yet.), this fixed the keyboard shortcut issue. Now I could quickly pull up the stats menu or perform some cheat codes!
Cheats
Even in the days before the internet, I learned about the infamous cheat code "razzle dazzle root beer" in Hero's Quest/QFG1, which helps avoid a lot of excess stats grinding (and I've done PLENTY of that over the past several decades). As I mentioned in the previous section, with the initial version of DOSBox-X I used, the CTRL key did not work, which resulted in the keyboard shortcuts being useless, and it also meant that it was not possible to select cheat codes if CTRL and ALT meta keys were not recognized. The following are links for the QFG1 cheats and debug codes to modify stats, inventory, and other debugging information.
But even if that was not possible, there are other tools which can hack the character's save file which is used to transfer between Quest for Glory games. The most prominent tools I found were QFG Importer and QFG Character Editor. This latter tool is older and only works with files exported from the first two games, but there is a web interface (in addition to an archived Windows program). QFG Importer is newer and is a Windows program which can work with the exported .sav files from the first four games.
Not related to the Japanese version of Quest for Glory 1 specifically, but there is now a QFG1 Randomizer program which randomly switches the location of inventory items throughout the game, which gives the game an interesting twist. It's differences like this which inspired me to play the Japanese version of QFG1 — to add something new to a game I've been playing repeatedly since it was first released.
In preparation of the upcoming Legend of Zelda: Tears of the Kingdom, I checked how much freespace was available on my Nintento Switch and its 128GB microSD card. After nearly six years of use, the system was finally starting to get somewhat full, especially when a number of games and demos had been downloaded (hence my preference to still get a physical version of games for a variety of reasons). This led me down the path to learn how to transfer the data on the old microSD card to a newer, larger microSD card, but while using a Mac.
The basic instructions to transfer the data between two microSD cards seemed fairly straightforward by just copying the contents of the first SD card to a computer, then copy the files to the new SD card. According to Nintendo's website, it recommends using Windows, which might have avoided some of the issues I would later encounter in my experiments, but I will detail on how to do this successfully on a Mac.
Upon my first attempt to transfer the files, I was getting some error on the Switch that said the new SD card couldn't be read. After mulling it over a bit, I assumed that macOS might have added some cruft to the files (dot files and the such) which might have confused the Switch. Time to start over by formatting the SD card, which can be done from the Switch (System Settings > System > Formatting Options > Format microSD Card) or via a 3rd party tool like SD Card Formatter.
SD Card Formatter
Despite what SDCard's site mentions, version 5.0.2 of the SD Card Formatter is a universal app for Intel, Apple Silicon, and (surprise!) PowerPC processors.
It is definitely a surprise to see that this app is essentially a mega universal binary, which contains binaries for Apple Silicon (M1, M2, etc.), Intel (both 32 and 64 bit), and PowerPC. I checked the Info.plist and it does say that the minimum version is 10.5, so it does look like it might be able to run on a 20 year old laptop (like my PowerBook G4). A very welcome surprise, and well done Tuxera. My own erasing app Permanent Eraser was a Universal Binary for PowerPC and Intel until fairly recently, but this is the first case I've seen an app built for PowerPC, Intel, and Apple Silicon. I'm guessing that it requires multiple builds, and then a tool like lipo is used to combine the binaries together.
Seeing this program is interesting and stirs some interest in how it "properly" formats an SD card, which Nintendo says "Nintendo products strictly adhere to the SD card standard." The Switch can format the SD card, and creates a couple of folders inside the Nintendo folder (Album, Contents, save).
The Fix
After reformatting the 512GB SD card in the Switch again, I brought it back over to my Mac, but I was careful to not open up the SD card in Finder (which can decorate a filesystem with .DS_Store files). Instead, I just ran this command from the Terminal:
Where ~/Desktop/Nintendo/ is the folder where I copied the contents of the original microSD card. Then, for good measure, I also ran:
dot_clean -m /Volumes/Untitled/
I had never heard of dot_clean before, until I came across this Reddit post. According to a Lifehacker article, dot_clean came out in Mac OS X Leopard (10.5). The Leopard man page for dot_clean says it dates back to June 28, 2006. I've dealt with cleaning up odd cruft in apps and file systems before, so this definitely seems quite handy and I wish I had known about this a long time ago. Despite these unexpected headaches — learning!
If these steps don't work, then try this bevy of commands next:
I was in the process of updating a new Mac port of a game developed with Adventure Game Studio (AGS), and after going through the standard steps, I encountered a confusing error when trying to launch the game.
"MyGreatApp" can’t be opened because Apple cannot check it for malicious software. This software needs to be updated. Contact the developer for more information.
Odd, curious, and frustrating. Since this new build was using the more recent 3.5.1 version of AGS, I assumed that the Mac shell I've been using for 3.5 was causing this mysterious error. However, I did not have the appropriate shell app, so I would need to go and create it...and in the process finally tackle something I've been intending to do for the past year — make a universal binary which can support both Intel and Apple Silicon processors.
The following steps will create a Mac shell app for an AGS game, which I then use to populate using the AGS resources (cfg, vox, exe) from a Windows version of a game.
How to build an AGS Mac shell app:
Pull the code from https://github.com/adventuregamestudio/ags.
Switch to another branch if you need to build for a particular version of AGS. For this particular example, I switched to the branch release-3.5.1.
Copy the build_ags.sh script into the ags folder. The script should be in the same folder which contains the CMakeLists.txt file. This will be important in a bit.
Next is the step to ensure that this will build a universal binary so it runs natively on both Intel and Apple Silicon. Open the CMakeLists.txt file. At line 6 (or before the project() function), add the line: set(CMAKE_OSX_ARCHITECTURES "arm64;x86_64" CACHE STRING "" FORCE)
Ensure that the build_ags.sh script has proper permissions: chmod 755 build_ags.sh
Run the script: ./build_ags.sh
After a few minutes, this will create a new folder named build_release and will generate a shell Mac app named AGS.app.
Troubleshooting:
I encountered a couple of issues when trying to build the AGS shell on my newer Mac, which seemed to be missing some critical pieces which had been on my older Mac.
% ./build_ags.sh
./build_ags.sh: line 8: cmake: command not found
make: *** No targets specified and no makefile found. Stop.
Looks like I was missing cmake on my new machine. To verify, I ran which cmake and it returned cmake not found. When I checked my old Mac, these are the details I had about cmake:
% which cmake
/usr/local/bin
% cmake --version
cmake version 3.18.0
CMake suite maintained and supported by Kitware (kitware.com/cmake).
That version of cmake had likely been installed by Xcode or manually installed some time in the distant past. On my new machine, I just used Homebrew to install it via the command: brew install cmake
To verify, I checked the new location and version of cmake.
% which cmake
/opt/homebrew/bin/cmake
% cmake --version
cmake version 3.25.2
CMake suite maintained and supported by Kitware (kitware.com/cmake).
Much better. However, I also discovered that the xcode-select path was not pointing to the desired location of the current version of Xcode. Generally when running a utility like stapler, I will prefix the command with xcrun, which greatly helps in locating the associated utility. But in case of building the AGS project encountered a similar issue, it would be best to fix this by updating the xcode-select path.
% stapler
xcode-select: error: tool 'stapler' requires Xcode, but active developer directory
'/Library/Developer/CommandLineTools' is a command line tools instance
% xcode-select -p
/Library/Developer/CommandLineTools
% sudo xcode-select -s /Applications/Xcode.app/Contents/Developer
% xcode-select -p
/Applications/Xcode.app/Contents/Developer
Despite some of the unexpected frustration I encountered creating this port, it did finally force my hand to build a new version of the Mac shell app, plus learn how to configure a Universal Binary for modern Macs, which surprisingly turned out to be quite simple.